Обучение ценностям
Теперь переходим к загрузке ценностей — серьезная проблема, которую придется решать довольно мягким методом. Он состоит в обучении ИИ ценностям, которые мы хотели бы ему поставить. Для этого потребуется хотя бы неявный критерий их отбора. Можно настроить ИИ так, чтобы он действовал в соответствии со своими представлениями об этих неявно заданных ценностях. Данные представления он будет уточнять по мере расширения своих знаний о мире.
В отличие от метода мотивационных строительных лесов, когда ИИ наделяется временной конечной целью, которая потом заменяется на отличную от нее постоянную, в методе обучения ценностям конечная цель не меняется на стадии разработки и функционирования ИИ. Обучение меняет не саму цель, а представления ИИ об этой цели.
Таким образом, у ИИ должен быть критерий, при помощи которого он мог бы определять, какие объекты восприятия содержат свидетельства в пользу некоторой гипотезы, что представляет собой конечная цель, а какие — против нее. Определить подходящий критерий может быть трудно. Отчасти эта трудность связана с самой задачей создания ИИ, которому требуется мощный механизм обучения, способный определять структуру окружающего мира на основании ограниченных сигналов от внешних датчиков. Этой проблемы мы касаться не будем. Но даже если считать задачу создания сверхразумного ИИ решенной, остаются трудности, специфические для проблемы загрузки системы ценностей. В случае метода обучения целям они принимают форму определения критерия, который связывает воспринимаемые потоки информации с гипотезами относительно тех или иных целей.
Прежде чем глубже погрузиться в метод обучения ценностям, было бы полезно проиллюстрировать идею на примере. Возьмем лист бумаги, напишем на нем определение какого-то набора ценностей, положим в конверт и заклеим его. После чего создадим агента, обладающего общим интеллектом человеческого уровня, и зададим ему следующую конечную цель: «Максимизировать реализацию ценностей, описание которых находится в этом конверте». Что будет делать агент?
Он не знает, что содержится в конверте. Но может выстраивать гипотезы и присваивать им вероятности, основываясь на всей имеющейся у него информации и доступных эмпирических данных. Например, анализируя другие тексты, написанные человеком, или наблюдая за человеческим поведением и отмечая какие-то закономерности. Это позволит ему выдвигать догадки. Не нужно иметь диплом философа, чтобы предположить, что, скорее всего, речь идет о заданиях, связанных с определенными ценностями: «минимизируй несправедливость и бессмысленные страдания» или «максимизируй доход акционеров», вряд ли его попросят «покрыть поверхность всех озер пластиковыми пакетами».
Приняв решение, агент начинает действовать так, чтобы реализовать ценности, которые, по его мнению, с наибольшей вероятностью содержатся в конверте. Важно, что при этом он будет считать важной инструментальной целью как можно больше узнать о содержимом конверта. Причина в том, что агент мог бы лучше реализовать почти любую конечную ценность, содержащуюся в конверте, если бы знал ее точную формулировку — тогда он действовал бы гораздо эффективнее. Агент также обнаружит конвергентные инструментальные причины (описанные в главе седьмой): неизменность целей, улучшение когнитивных способностей, приобретение ресурсов и так далее. И при этом, если исходить из предположения, что он присвоит достаточно высокую вероятность тому, что находящиеся в конверте ценности включают благополучие людей, он не станет стремиться реализовать эти инструментальные цели за счет немедленного превращения планеты в компьютрониум, тем самым уничтожив человеческий вид, поскольку это будет означать риск окончательно лишиться возможности достичь конечной ценности.
Такого агента можно сравнить с баржей, которую несколько буксиров тянут в разные стороны. Каждый буксир символизирует какую-то гипотезу о конечной ценности. Мощность двигателя буксира соответствует вероятности гипотезы, поэтому любые новые свидетельства меняют направление движения баржи. Результирующая сила перемещает баржу по траектории, обеспечивающей обучение (неявно заданной) конечной ценности и позволяющей обойти мели необратимых ошибок; а позднее, когда баржа достигнет открытого моря, то есть более точного знания конечной ценности, буксир с самым мощным двигателем потянет ее по самому прямому или благоприятному маршруту.
Метафоры с конвертом и баржей иллюстрируют принцип, лежащий в основе метода обучения ценностям, но обходят стороной множество критически важных технических моментов. Они станут заметнее, когда мы начнем описывать этот метод более формально (см. врезку 10).
Как можно наделить ИИ такой целью: «максимизируй реализацию ценностей, изложенных в записке, лежащей в запечатанном конверте»? (Или другими словами, как определить критерий цели — см. врезку 10.) Чтобы сделать это, необходимо определить место, где описаны ценности. В нашем примере это требует указания ссылки на текст в конверте. Хотя эта задача может показаться тривиальной, но и она не без подводных камней. Упомянем лишь один: критически важно, чтобы ссылка была не просто на некий внешний физический объект, но на объект по состоянию на определенное время. В противном случае ИИ может решить, что наилучший способ достичь своей цели — это заменить исходное описание ценности на такое, которое значительно упростит задачу (например, найти большее число для некоторого целого числа). Сделав это, ИИ сможет расслабиться и бить баклуши — хотя скорее за этим последует опасный отказ по причинам, которые мы обсуждали в главе восьмой. Итак, теперь встал вопрос, как определить это время. Мы могли бы указать на часы: «Время определяется движением стрелок этого устройства», — но это может не сработать, если ИИ предположит, что в состоянии манипулировать временем, управляя стрелками часов. И он будет прав, если определять «время» так, как это сделали мы. (В реальности все будет еще сложнее, поскольку соответствующие ценности не будут изложены в письменном виде. Скорее всего, ИИ придется выводить ценности из наблюдений за внешними структурами, содержащими соответствующую информацию, такими как человеческий разум.)
ВРЕЗКА 10. ФОРМАЛИЗАЦИЯ ОБУЧЕНИЯ ЦЕННОСТЯМ
Чтобы яснее понять метод, опишем его более формально. Читатели, которые не готовы погружаться в математические выкладки, могут этот раздел пропустить.
Предположим, что есть упрощенная структура, в которой агент взаимодействует со средой конечного числа моментов[462]. В момент k агент выполняет действие yk, после чего получает ощущение xk. История взаимодействия агента со средой в течение жизни m описывается цепочкой y1x1y2x2…ymxm (которую мы представим в виде yx1:m или yx?m). На каждом шаге агент выбирает действие на основании последовательности ощущений, полученных к этому моменту.
Рассмотрим вначале обучение с подкреплением. Оптимальный ИИ, обучающийся с подкреплением (ИИ-ОП), максимизирует будущую ожидаемую награду. Тогда выполняется уравнение[463]

Последовательность подкреплений rk, …, rm вытекает из последовательности воспринимаемых состояний среды xk:m, поскольку награда, полученная агентом на каждом шаге, является частью восприятия, полученного на этом шаге.
Мы уже говорили, что такого рода обучение с подкреплением в нынешних условиях не подходит, поскольку агент с довольно высоким интеллектом поймет, что обеспечит себе максимальное вознаграждение, если сможет напрямую манипулировать сигналом системы наград (эффект самостимуляции). В случае слабых агентов это не будет проблемой, поскольку мы сможем физически предотвратить их манипуляции с каналом, по которому передаются вознаграждения. Мы можем также контролировать их среду, чтобы они получали вознаграждение только в том случае, если их действия согласуются с нашими ожиданиями. Но у любого агента, обучающегося с подкреплением, будут иметься серьезные стимулы избавиться от этой искусственной зависимости: когда его вознаграждения обусловлены нашими капризами и желаниями. То есть наши отношения с агентом, обучающимся с подкреплением, фундаментально антагонистичны. И если агент силен, это может быть опасно.
Варианты эффекта самостимуляции также могут возникнуть у систем, не стремящихся получить внешнее вознаграждение, то есть у таких, чьи цели предполагают достижение какого-то внутреннего состояния. Скажем, в случае систем «актор–критик», где модуль актора выбирает действия так, чтобы минимизировать недовольство отдельного модуля критика, который вычисляет, насколько соответствует поведение актора требуемым показателям эффективности. Проблема этой системы следующая: модуль актора может понять, что способен минимизировать недовольство критика, изменив или вовсе ликвидировав его — как диктатор, распускающий парламент и национализирующий прессу. В системах с ограниченными возможностями избежать этой проблемы можно просто: не дав модулю актора никаких инструментов для модификации модуля критика. Однако обладающий достаточным интеллектом и ресурсами модуль актора всегда сможет обеспечить себе доступ к модулю критика (который фактически представляет собой лишь физический вычислительный процесс в каком-то компьютере)[464].
Прежде чем перейти к агенту, который проходит обучение ценностям, давайте в качестве промежуточного шага рассмотрим другую систему, максимизирующую полезность на основе наблюдений (ИИ-МНП). Она получается путем замены последовательности подкреплений (rk + … + rm) в ИИ-ОП на функцию полезности, которая может зависеть от всей истории будущих взаимодействий ИИ:
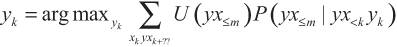
Эта формула позволяет обойти проблему самостимуляции, поскольку функцию полезности, зависящую от всей истории взаимодействий, можно разработать так, чтобы наказывать истории взаимодействия, в которых проявляются признаки самообмана (или нежелания агента прикладывать достаточные усилия, чтобы получить точную картину действительности).
Таким образом, ИИ-МНП дает возможность обойти проблему самостимуляции в принципе. Однако, чтобы ею воспользоваться, нужно задать подходящую функцию полезности на классе всех возможных историй взаимодействия — а это очень трудная задача.
Возможно, более естественным было бы задать функцию полезности непосредственно в терминах возможных миров (или свойств возможных миров, или теорий о мире), а не в терминах историй взаимодействия агента. Используя этот подход, формулу оптимальности ИИ-МНП можно переписать и упростить:

Здесь E — это все свидетельства, доступные агенту (в момент, когда он принимает решение), а U — функция полезности, которая присваивает полезность некоторому классу возможных миров. Оптимальный агент будет выбирать действия, которые максимизируют ожидаемую полезность.
Серьезная проблема этих формул — сложность задания функции полезности. И это наконец возвращает нас к проблеме загрузки ценностей. Чтобы функцию полезности можно было получить в процессе обучения, мы должны расширить наше формальное определение и допустить неопределенность функции полезности. Это можно сделать следующим образом (ИИ-ОЦ)[465]:

где v(—) — функция от функций полезности для предположений относительно функций полезности. v(U) — предположение, что функция полезности U удовлетворяет критерию ценности, выраженному v[466]
То есть чтобы решить, какое действие выполнять, нужно действовать следующим образом: во-первых, вычислить условную вероятность каждого возможного мира w (учитывая все возможные свидетельства и исходя из предположения, что должно быть выполнено действие y); во-вторых, для каждой возможной функции U вычислить условную вероятность того, что U удовлетворяет критерию ценности v (при условии, что w — это реальный мир); в-третьих, для каждой возможной функции полезности U вычислить полезность возможного мира w; в-четвертых, использовать все эти значения для расчета ожидаемой полезности действия y; в-пятых, повторить эту процедуру для всех возможных действий и выполнить действие, имеющее самую высокую ожидаемую полезность (используя любой метод выбора из равных значений в случае возникновения таковых). Понятно, что таким образом описанная процедура — предполагающая явное рассмотрение всех возможных миров — вряд ли реализуема с точки зрения потребности в вычислительных ресурсах. ИИ придется использовать обходные пути, чтобы аппроксимировать это уравнение оптимальности.
Остается вопрос, как определить критерий ценности v[467] Если у ИИ появится адекватное представление этого критерия, он, в принципе, сможет использовать свой интеллект для сбора информации о том, какие из возможных миров с наибольшей вероятностью могут оказаться реальными. После чего применить критерий ценности для каждого потенциально реального мира, чтобы выяснить, какая целевая функция удовлетворяет критерию в мире w. То есть формулу ИИ-ОЦ можно считать одним из способов идентифицировать и выделить ключевую сложность в методе обучения ценностям — как представить v. Формальное описание задачи высвечивает также множество других сложностей (например, как определить Y, W и U), с которыми придется справиться прежде, чем метод можно будет использовать[468].
Другая трудность кодирования цели «максимизируй реализацию ценностей из конверта» заключается в том, что даже если в этом письме описаны все правильные ценности и система мотивации ИИ успешно воспользуется этим источником, ИИ может интерпретировать описания не так, как предполагалось его создателями. Это создаст риск порочной реализации, описанной в главе восьмой.
Поясним, что трудность здесь даже не в том, как добиться, чтобы ИИ понял намерения людей. Сверхразум справится с этим без проблем. Скорее, трудность заключается в том, чтобы ИИ был мотивирован на достижение описанных целей так, как предполагалось. Понимание наших намерений это не гарантирует: ИИ может точно знать, что мы имели в виду, и не обращать никакого внимания на эту интерпретацию наших слов (используя в качестве мотивации иную их интерпретацию или вовсе на них не реагируя).
Трудность усугубляется тем, что в идеале (по соображениям безопасности) правильную мотивацию следует загрузить в зародыш ИИ до того, как он сможет выстраивать представления любых человеческих концепций и начнет понимать намерения людей. Это потребует создания какого-то когнитивного каркаса, в котором будет предусмотрено определенное место для системы мотивации ИИ как хранилища его конечных ценностей. Но у ИИ должна быть возможность изменять этот когнитивный каркас и развивать свои способности представления концепций по мере узнавания мира и роста интеллекта. ИИ может пережить эквивалент научной революции, в ходе которой его модель мира будет потрясена до основания, и он, возможно, столкнется с онтологическим кризисом, осознав, что его предыдущее видение целей было основано на заблуждениях и иллюзиях. При этом, начиная с уровня интеллекта, еще не достигающего человеческого, и на всех остальных этапах развития, вплоть до сверхразума галактических масштабов, поведение ИИ должно определяться, по сути, неизменной конечной системой ценностей, которую благодаря этому развитию ИИ понимает все лучше; при этом зрелый ИИ, скорее всего, будет понимать ее совсем не так, как его разработчики, хотя эта разница возникнет не в результате случайных или враждебных действий ИИ, но скорее из добрых побуждений. Как бороться с этим, еще неясно[469] (см. врезку 11).
Подводя итоги, стоит сказать, что пока неизвестно, как использовать метод обучения ценностям для формирования у ИИ ценностной системы, приемлемой для человека (впрочем, некоторые новые идеи можно найти во врезке 12). В настоящее время этот метод следует считать скорее перспективным направлением исследований, нежели доступной для применения техникой. Если удастся заставить его работать, он может оказаться почти идеальным решением проблемы загрузки ценностей. Помимо прочих преимуществ, его использование станет естественным барьером для проявлений с нашей стороны преступной безнравственности, поскольку зародыш ИИ, способный догадаться, какие ценностные цели могли загрузить в него программисты, может додуматься, что подобные действия не соответствуют этим ценностям и поэтому их следует избегать как минимум до тех пор, пока не будет получена более определенная информация.
Последний, но немаловажный, вопрос — что положить в конверт? Или, если уйти от метафор, каким ценностям мы хотели бы обучить ИИ? Но этот вопрос одинаков для всех методов решения проблемы загрузки ценностей. Вернемся к нему в главе тринадцатой.
ВРЕЗКА 11. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ, КОТОРЫЙ ХОЧЕТ БЫТЬ ДРУЖЕСТВЕННЫМ
Элиезер Юдковский попытался описать некоторые черты архитектуры зародыша ИИ, которая позволила бы ему вести себя так, как описано выше. В его терминологии такой ИИ должен использовать «семантику внешних ссылок»[470]. Чтобы проиллюстрировать основную идею Юдковского, давайте предположим, что мы хотим создать дружественный ИИ. Его исходная цель — попытаться представить себе некое свойство F, но изначально ИИ почти ничего об F не знает. Ему известно лишь, что F — некоторое абстрактное свойство. И еще он знает, что когда программисты говорят о дружественности, они, вероятно, пытаются передать информацию об F. Поскольку конечной целью ИИ является составление формулировки понятия F, его важной инструментальной целью становится больше узнать об F. По мере того как ИИ узнает об F все больше, его поведение все сильнее определяется истинным содержанием этого свойства. То есть можно надеяться, что чем больше ИИ узнаёт и чем умнее становится, тем более дружелюбным он становится.
Разработчики могут содействовать этому процессу и снизить риск того, что ИИ совершит какую-то катастрофическую ошибку, пока не до конца понимает значение F, обеспечивая его «заявлениями программистов» — гипотезами о природе и содержании F, которым изначально присваивается высокая вероятность. Например, можно присвоить высокую вероятность гипотезе «вводить программистов в заблуждение недружественно». Однако такие заявления не являются «истиной по определению», аксиомами концепции дружелюбия. Скорее всего, это лишь начальные гипотезы, которым рациональный ИИ будет присваивать высокую вероятность как минимум до тех пор, пока доверяет эпистемологическим способностям программистов больше, чем своим.
Юдковский также предложил использовать то, что он называет «семантика причинной валидности». Идея состоит в том, чтобы ИИ делал не в точности то, что программисты говорят ему делать, но скорее то, что они пытались ему сказать сделать. Пытаясь объяснить зародышу ИИ, что такое дружелюбие, они могли совершить ошибку в своих объяснениях. Более того, сами программисты могли не до конца понимать истинную природу дружелюбия. Поэтому хочется, чтобы ИИ мог исправлять ошибки в их умозаключениях и выводить истинное или предполагавшееся значение из неидеальных объяснений, которые дали ему программисты. Например, воспроизводить причинные процессы появления представлений о дружелюбии у самих программистов и о способах его описания; понимать, что в процессе ввода информации об этом свойстве они могли сделать опечатку; попытаться найти и исправить ее. В более общем случае ИИ следует стремиться исправить последствия любого вмешательства, искажающего поток информации о характере дружелюбия, на всем ее пути от программистов до ИИ (где «искажающий» понимается в эпистемологическом смысле). В идеале по мере созревания ИИ ему следует преодолеть все когнитивные искажения и прочие фундаментально ошибочные концепции, которые могли бы помешать программистам до конца понять, что такое дружелюбие.
ВРЕЗКА 12. ДВЕ НОВЕЙШИЕ ИДЕИ — ПРАКТИЧЕСКИ НЕЗРЕЛЫЕ, ПОЧТИ ПОЛУСЫРЫЕ
Подход, который можно назвать «Аве Мария»[471], основан на надежде, что где-то во Вселенной существуют (или вскоре возникнут) цивилизации, успешно справившиеся со взрывным развитием интеллекта и в результате пришедшие к системам ценностей, в значительной степени совпадающим с нашими. В этом случае мы можем попробовать создать свой ИИ, который будет мотивирован делать то же, что и их интеллектуальные системы. Преимущества этого подхода состоят в том, что так создать нужную мотивацию у ИИ может быть легче, чем напрямую.
Чтобы эта схема могла сработать, нашему ИИ нет необходимости связываться с каким-то инопланетным ИИ. Скорее, в своих действиях он должен руководствоваться оценками того, что тот мог бы захотеть сделать. Наш ИИ мог бы смоделировать вероятные исходы взрывного развития интеллекта где-то еще, и по мере превращения в сверхразум делать это все точнее. Идеальных знаний от него не требуется. У взрывного развития интеллекта может быть широкий диапазон возможных исходов, и нашему ИИ нужно постараться определиться с предпочтениями относительно типов сверхразума, которые могут быть связаны с ними, взвешенными на их вероятности.
В этой версии подхода «Аве Мария» требуется, чтобы мы разработали конечные ценности для нашего ИИ, согласующиеся с предпочтениями других систем сверхразума. Как это сделать, пока до конца неясно. Однако структурно сверхразумные агенты должны отличаться, чтобы мы могли написать программу, которая служила бы детектором сверхразума, анализируя модель мира, возникающую в нашем развивающемся ИИ, в поиске характерных для сверхразума элементов представления. Затем программма-детектор могла бы каким-то образом извлекать предпочтения рассматриваемого сверхразума (из его представления о нашем ИИ)[472]. Если нам удастся создать такой детектор, его можно будет использовать для определения конечных ценностей нашего ИИ. Одна из трудностей заключается в том, что нам нужно создать такой детектор раньше, чем мы будем знать, какой каркас представления разработает наш ИИ. Программа-детектор должна уметь анализировать незнакомые каркасы представления и извлекать предпочтения представленных в них систем сверхразума. Это кажется непростой задачей, но, возможно, какое-то ее решение удастся найти[473].
Если получиться реализовать основной подход, можно будет немедленно заняться его улучшением. Например, вместо того чтобы следовать предпочтениям (точнее, их некоторой взвешенной композиции) каждого инопланетного сверхразума, у нашего ИИ может иметься фильтр для отбора подмножества инопланетных ИИ (чтобы он мог брать пример с тех, чьи ценности совпадают с нашими). Например, в качестве критерия включения ИИ в это подмножество может использоваться источник его возникновения. Некоторые обстоятельства создания ИИ (которые мы должны уметь определить в структурных терминах) могут коррелировать с тем, в какой степени появившийся в результате ИИ может разделять наши ценности. Возможно, большее доверие у нас вызовут ИИ, первоисточником которых была полная эмуляция головного мозга, или зародыш ИИ, в котором почти не использовались эволюционные механизмы, или такие, которые возникли в результате медленного контролируемого взлета. (Если брать в расчет источник возникновения ИИ, мы также сможем избежать опасности присвоить слишком большой вес тем ИИ, которые создают множество своих копий, — а на самом деле избежать создания для них стимула делать это.) Можно также внести в этот подход множество других улучшений.
Подход «Аве Мария» подразумевает веру, что где-то существуют другие системы сверхразума, в значительной степени разделяющие наши ценности[474]. Это означает, что он неидеален.
Однако технические препятствия, стоящие на пути реализации подхода «Аве Мария», хотя и значительны, но вполне могут оказаться менее сложными, чем при других подходах. Может быть, имеет смысл изучать подходы пусть и не самые идеальные, но более простые в применении, — причем не для использования, а скорее, чтобы иметь запасной план на случай, если к нужному моменту идеальное решение не будет найдено.
Недавно Пол Кристиано предложил еще одну идею решения проблемы загрузки ценностей[475] Как и при «Аве Марии», это метод обучения ценностям, который предполагает определение критерия ценности не при помощи трудоемкой разработки, а скорее фокусировки. В отличие от «Аве Марии», здесь не предполагается существования других сверхразумных агентов, которые мы используем в качестве ролевых моделей для нашего собственного ИИ. Предложение Кристиано с трудом поддается короткому объяснению — оно представляет собой цепочку сложных умозаключений, — но можно попытаться как минимум указать на его основные элементы.
Предположим, мы получаем: а) математически точное описание мозга конкретного человека; б) математически строго определенную виртуальную среду, содержащую идеализированный компьютер с произвольно большим объемом памяти и сверхмощным процессором. Имея а и б, можно определить функцию полезности U как выходной сигнал, который выдает мозг человека после взаимодействия с этой средой. U может быть математически строго определенным объектом, но при этом таким, который (в силу вычислительных ограничений) мы неспособны описать конкретно. Тем не менее U может служить в качестве критерия ценности при обучении ИИ системе ценностей. При этом ИИ будет использовать различные эвристики, чтобы строить вероятностные гипотезы о том, что представляет собой U.
Интуитивно хочется, чтобы U была такой функцией полезности, которую нашел бы соответствующим образом подготовленный человек, обладающий произвольно большим объемом вычислительных ресурсов, достаточным, например, для создания астрономически большого количества своих имитационных моделей, способных помогать ему в поиске функции полезности или в разработке процесса ее поиска. (Мы сейчас затронули тему конвергентного экстраполированного волеизъявления, которую подробнее рассмотрим в тринадцатой главе.)
Задача описания идеализированной среды кажется относительно простой: мы можем дать математическое описание абстрактного компьютера с произвольно большой емкостью; а также при помощи программы виртуальной реальности описать, скажем, комнату со стоящим в ней компьютерным терминалом (олицетворяющим тот самый абстрактный компьютер). Но как получить математически точное описание мозга конкретного человека? Очевидный путь — его полная эмуляция, но что если эта технология еще не доступна?
Именно в этом и проявляется ключевая инновация, предложенная Кристиано. Он говорит, что для получения математически строгого критерия цели нам не нужна пригодная для практического использования вычислительная имитационная модель мозга, которую мы могли бы запустить. Нам нужно лишь (возможно, неявное и безнадежно сложное) ее математическое определение — а его получить гораздо легче. При помощи функциональной нейровизуализации и других средств измерения можно собрать гигабайты данных о связях между входными и выходными сигналами головного мозга конкретного человека. Собрав достаточное количество данных, можно создать наиболее простую имитационную математическую модель, которая учитывает все эти данные, и эта модель фактически окажется эмулятором рассматриваемого мозга. Хотя с вычислительной точки зрения нам может оказаться не под силу задача отыскать такую имитационную модель из имеющихся у нас данных, опираясь на них и используя математически строгие показатели сложности (например, какой-то вариант колмогоровской сложности, с которой мы познакомились во врезке 1 в первой главе), вполне реально эту модель определить[476].
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК